“尚跃智能”科研团队计划推出“数据可视化”“数据可流转化”的开放型数据流转平台。随着大数据和人工智能技术的发展,数据成为了当今社会最有价值的资源之一。但同时在数据的利用过程中,如何兼顾数据安全与隐私保护仍然是一个待解决的问题。基于数据隐私的产品应运而生,通过分布式机器学习技术,实现了在保护用户隐私的同时挖掘数据价值。
目前,该公司团队已准备推出开放服务平台1.0、AIGC智能数据生成平台,并整合产学研用各方资源搭建人工智能数据流转开放生态,探索通用人工智能数据流转产业化路径。
以下为尚立卓的演讲实录:
大家上午好!我是数据流转平台负责人尚立卓。
首先解释一下,我个人是大数据和计算机应用专业的理科出身,从事的是数据标注业务的研究。往年一直在人工智能领域深耕和挖掘,在大模型到来之后,我和我的团队提出了数据可视化,数据可交易化的想法,也参与过一些大模型项目,今天我作为一个人工智能领域的参与者,跟大家分享一下开放型数据流转平台相关的情况。
一、大模型目前正在面临非常大的制约
自从各大 AIGC 横空出世之后,大型语言模型(LLM)相关的研究与应用也层出不穷,尽管这些技术能够为我们提供更智能、精准和便利的信息和服务,但也带来了一系列的难题和风险。
大模型面对的挑战主要可以分为三大类:“设计”、“行为”和“科学”,其中,大模型的“设计”与部署前的决策有关,在部署过程中会出现“行为”的挑战,而“科学”的挑战则阻碍了研究大模型的学术进步。
挑战 1:难以理解的数据集
由于各团队在扩展预训练的数据量,随着现如今预训练数据集规模的扩大,个人难以完整阅读和检查整个文档的质量。
如图所示,近年来预训练数据集变得不可控,因为它们的大小和多样性迅速增长,而并非所有的数据集都是公开可用的。
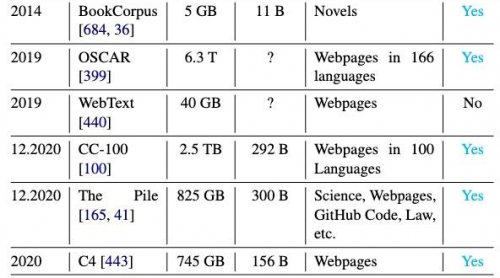
因此,当GPT发布之后,我们就认为数据和知识必将是一个未来的方向,我们现在也看到大多数大模型已经处于“学识渊博”的状态不知道该去学习什么了。
挑战 2:对分词器的依赖
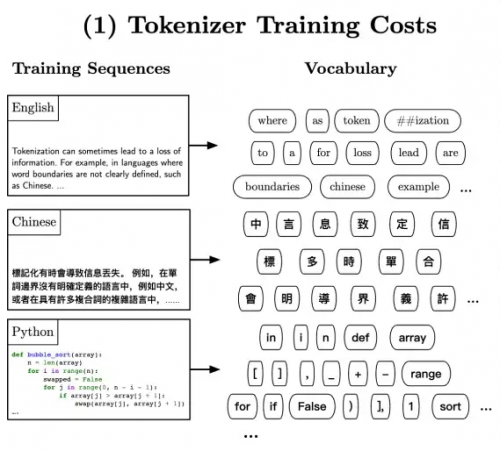
大语言模型的训练和运行通常依赖于特定的分词器,这可能对其性能和适应性产生影响。
分词(Tokenization)是将一系列单词或字符拆分为较小单元(即 token)的过程,以便输入模型。其中一种常见的分词方法是子词分词(subword tokenization),将单词分解为子词或 WordPieces。这样做的目的是有效处理模型词汇表中的罕见和未登录词汇,同时限制每个序列的 token 数量,以减少计算复杂性。子词分词器通常通过无监督训练来构建词汇表,并可选地使用合并规则以提高对训练数据的编码效率。
然而,分词的必要性也存在一些缺点:
1;不同语言传达相同信息所需的 token 数量差异很大,这可能导致基于 token 数量计费的 API 语言模型在许多受支持的语言中过度收费且结果不佳,特别是在这些 API 在本身就较不可负担的地区使用。
2;分词器和预训练语料库之间的不一致性可能导致错误 token,进而导致模型行为异常。
3;不同语言的分词方案也面临一些挑战,特别是对于非空格分隔的语言如中文或日文。现有的子词分词方法主要是贪婪算法,试图以尽可能高效的方式编码语言,从而导致对较多语言共享的子词的偏好,不利于低资源语言的 token。
4;此外,分词器会带来计算负担、语言依赖性、处理新词、固定词汇表大小、信息丢失和人类可解释性等多个挑战。
挑战 3:高昂的预训练成本
大型语言模型的训练需要大量的计算资源和时间,这可能会对其广泛应用产生限制。
训练 LLM 的主要消耗是在预训练过程中,需要数十万个计算小时、数百万元的成本,以及相当于数个普通美国家庭年度能源消耗量的能量。而近期提出的缩放定律认为,模型性能随着模型大小、数据集大小和训练中使用的计算量呈幂律关系,这种不可持续的情况被称为“红色 AI”。
为了解决这些问题,有两条研究路线:
1:计算最优训练方法:通过学习经验性的“缩放定律”,以实现在给定计算预算下最大化训练效率;
2:预训练目标:如图所示,利用各种目标进行自监督训练,其中不同的预训练目标会影响模型的数据效率和所需迭代次数。
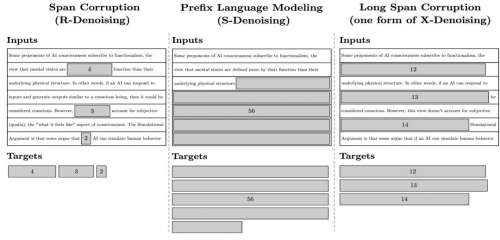
此外,还有其他研究方向,如并行策略、层叠模型、递增批量大小和最新权重平均等,这些方法在提高模型性能和减少计算成本方面具有一定效果。
1:预训练目标的选择包括语言建模、掩码语言建模、前缀语言建模、连续区间损坏和混合去噪等。
2:并行策略是解决训练和推理中巨大 LLM 规模的常见方法,其中模型并行(model parallelism)和流程并行(pipeline parallelism)是两种常见的策略。
所以,如何减少大模型的训练成本非常关键,直接影响到了大模型未来的发展空间和生存状态,我们的数据流转中心可以解决绝大多数大模型训练所需的数据和知识数据和知识。
二、人工智能过不去的“坎”
我和我团队起初在有这个想法的时候,就一直在做市场调研并且在考虑应该如何设计,将不同的数据集导入在一个平台里面供市场上有需求的的大模型公司进行训练学习。我在晚上休息的时候看到周鸿祎老师的视频启发到了我。
他说道:大模型之所以能有今天的能力最关键的还是要把人类产生的知识要训练进去,要教给他用但是在2021年训练GPT4的时候就已经耗尽了他们能找到的所有关于人类的文本知识。
也正是因为周老师的这句话坚定了我们要开发制造数据流转平台的信心。我们提出的数据流转中心和数据可视化就是要把目前人类所认知到的和未被市场商业化的数据给结合起来形成一个数据仓库集中起来,进而满足各种各样大模型的数据和知识需求。
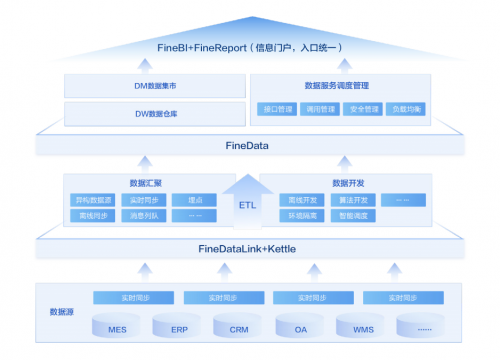
三、打造开放服务平台 1.0,做到数据流转合规化
数据合规一词,已经越来越被大众所熟知并认可,其中涵盖的合规内容很多,从全生命周期的角度,就包括收集合规、存储合规、使用合规、流转合规等等。根据我们的观察,流转阶段是目前普遍最不受重视的领域,例如,随便将个人信息/数据发在微信群、没有对接收方的数据处理行为进行监管等,更别提签订合同明确各方的权利义务了。但事实上,数据流转,可能是除了收集之外,离我们生活最近的一环。只要稍加留意,就会发现,数据流转的场景到处都是。例如,某宝上购物,买家信息先是给到平台,平台再给到商家;再如,代发工资,公司会将财务数据给到银行,等等。更何况,生产要素要最大化的发挥出价值,必须要充分的流动起来,从这个角度看,数据流动的合规化可能是数据合规链条中最重要的一环。那么数据流动如何做到合规呢?
1:明确合规红线。我们会基于风险维度的审查思路,梳理法律法规的相关要求以及结合企业内部的合规管理要求,设定合规审查红线,并将其作为合规审查的优先项;当出现触发合规审查红线的情形,则应拒绝接入相关数据,实现明确合规底线,提高审查效率的效果。合规审查红线可以根据数据源(即出售方)类型、数据类型、数据收集手段等方面予以全面考量。
2:数据来源的分类分级。在推进数据合规审查工作过程中,建立数据来源分类分级审查规则,风险评价指标和可结合采购业务场景、数据源的情况等予以综合确定。例如数据源类型、数据主体类型、数据类型、数据来源业务场景、数据应用业务场景等因素都会对数据来源合规审查的风险等级判断产生影响;其中,对于高风险数据源应当予以审慎审查。
3: 实现穿透审查。数据来源的合规审查应当坚持穿透性原则,对于多主体间流转、数据处理活动复杂的数据源审查应当穿透至底层数据,重点关注收集和提供过程中获得授权同意等的完整性、连续性。例如业务交互场景下收集和产生的数据是否可以用于其他目的,就需通过审查协议文本等确认数据源对数据所享有权益的具体范围。
四、服务于大模型,打造简单,优质,低成本的道路
我们为大模型开发高价值的开放平台,把无规律的数据提炼为高价值的数据提供给机器学习,提供“动力来源”,“提供粮食”像石油一样源源不断的给大模型输送。传播开放数据产生的价值,为大模型的训练提供有价值的数据为跨领域跨行业应用提升开放数据的利用建议,帮助用户突破行业间的认知壁垒,促进数据应用
我们不断追赶,不断深耕探索,从数据到算力和算法,我们一直在进步,公司将会一直在人工智能领域里钻研,同时也希望大家和我们一起共同推动人工智能的发展
谢谢大家!